
In this post, I’m going to show you the project that I developed for my Master’s Thesis while I was collaborating with my current research group. The code could be found on my GitHub and comprises the process of extracting features from the dataset UCF-101 using DenseTrajectories, as well as training and evaluating the model.
As regards to the motivation, at that time (around 2013), my group was collaborating with Ying Zheng, Hugo Larochelle, and Aaron Courville. While they were considering Convolutional Neural Networks (CNN) as a feature extractor and classification model, we wanted to evaluate in parallel the possibilities of a model that does not rely on CNN, to classify videos quickly without the dedicated Hardware that is required to use CNN.
I’m going to explain the different steps of the project, from dataset’s description, feature extraction and classification, to the final evaluation. For this first post, I will describe the dataset and the feature extractor. We will talk about both classification and evaluation in following posts.
Dataset: UCF-101
The dataset that we selected was UCF-101, a dataset that comprises over 13.000 short videos from Youtube. These videos show people doing different activities. Regarding videos’ properties, they have a resolution of 320×240 pixels at 25 fps, having a duration of 7,21 seconds on average.
The kind of actions represented is divided into five groups: human-human interaction, human-object interaction, body movement, playing musical instruments and sports. On every category, there are several actions, up to 101 in total. Therefore, this is a classification task with 101 classes. Some examples of these are represented in the underneath image. The official performance measure is the average classification accuracy over all classes.

We chose this dataset because it is used in the THUMOS 2013 competition and we wanted to compare our results to other approaches.
So, considering using this dataset, we developed a classification pipeline. This pipeline defines the feature extraction, the classifier and its training procedure, and evaluation.
Regarding the feature extraction, we used improved Dense Trajectories (iDT), an extractor that I will comment on later. As a classifier, although several teams were using Convolutional Neural Networks (CNN) for this task at that time (around 2014), we were interested in evaluating a more straightforward and faster model based on Feed Forward Networks without convolutions.
As well as a different model, we wanted to consider a different training procedure, that is, training the model with “patches” from the video and then providing an output for every patch. After this step, by using a fusion scheme that considers each patch’s output, classify the action. I will describe this process later as well.
Feature extraction: improved Dense Trajectories (iDT)
The main idea of this extractor is to discover where the action is happening, considering that the action implies movement and it has a “temporal trajectory”. Once this is detected, different features are extracted from this 3D volume. The following image describes the whole process.
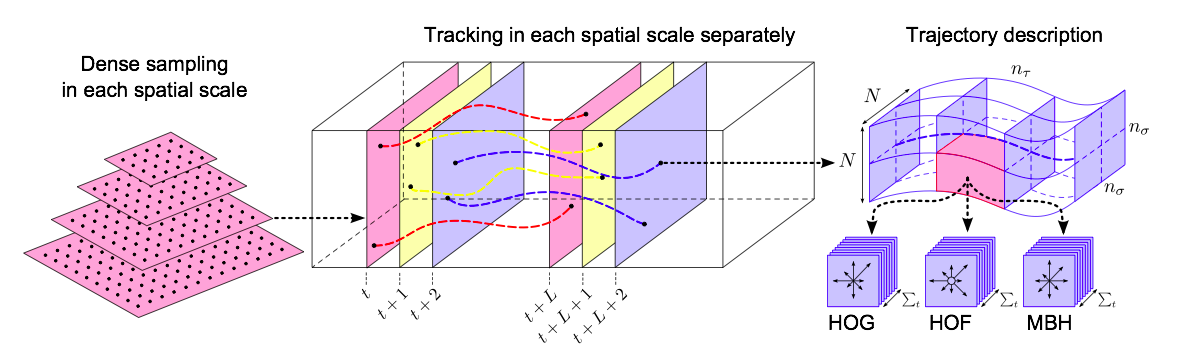
One example (PersonBoxing) from one of the videos from UCF-101, and one frame’s output with the detected movement.

Features are extracted around de detected movement, as a 3D patch. Regarding the different extracted features:
- Histograms of Oriented Gradients (HOG): Useful for identifying contours and shapes.
- Histograms of Optical Flow (HOF): Descriptor that captures the information related to the movement.
- Motion Boundary Histograms (MBH): In this case, this descriptor remove constant motion, reducing the influence of camera motion.
-
Trajectories’ information
All these values are composed in a 435 feature vector that describes one 3D patch from the video. Therefore, this vector will be the input for the classifier.
To obtain these features for all the videos, we used the SGE cluster available at the Research Center. By means of sharing the videos among different nodes, we were able to process the 13.000 videos in a reasonable time. Eventually, we extracted up to 1.000 feature vectors per video.
After completing the feature extraction step, we proceed with training the model.